








Businesses and financial institutions handle large amounts of documentation, forms, invoices, and transactional details. Manual document and form processing is time-consuming and exhausting, but evolving technology offers a solution. Optical Character Recognition (OCR) technology has been a prominent tool in form processing, automating the digitization of documents.
However, as technology advances, the need for capable, more efficient solutions has become apparent to customers. Modern OCR software improves the speed and accuracy of handwriting, allowing businesses to manage information more efficiently.
This shift to advanced OCR technologies represents a vital step towards improved service, operational efficiency, and productivity, all key to meeting the growing demands of customers in the current engaged business environment.
This comprehensive article will help you understand how OCR form processing works, the types of forms, the value and benefits of OCR forms, applications of OCR form processing, the challenges involved, and how to stay relevant with the latest advancements in free OCR software.
How OCR form processing works

Optical Character Recognition (OCR) is a widely used technology that converts handwritten, typed, or scanned text from images and text within pixels of the scanned images into machine-readable text. This capability makes OCR an intelligent tool for processing forms and other documents.
Explanation of OCR technology
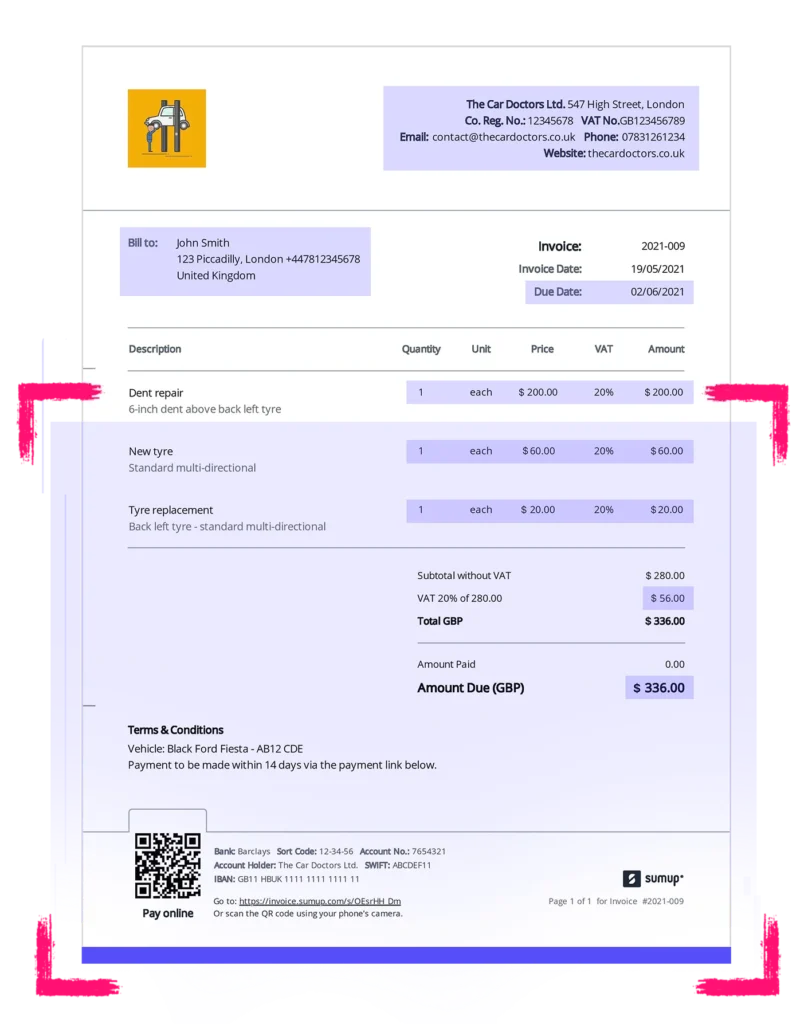
OCR form and document processing refers to the application of OCR technology to extract data from forms. These forms can include contracts, surveys, applications, medical records, etc. This process automates data extraction and document processing, improving efficiency and accuracy in handling diverse types of documents.
Before understanding the OCR form processing workflow, learning the different types of forms involved is necessary. Let’s break it down.
Type of forms: structures and unstructured
Structured forms: Structured forms consist of clearly defined text blocks with fields that consistently appear on each page in the same locations. The only variation lies in the information entered into each field. OCR technology is highly effective with structured forms because the data remains in fixed positions on each page, allowing for accurate and efficient data extraction.
Unstructured forms: An unstructured form is a document that lacks a predefined layout or consistent format. Unlike structured forms with clearly defined fields and sections, unstructured forms can contain information presented in various ways, making data extraction more challenging. Examples of unstructured forms include emails, letters, reports, PDFs, forms, and free-text fields within documents.
Semi-structured forms: Semi-structured forms present a unique challenge because the location of identifiers and checkboxes can vary, as do the data fields. This variability in key poses a problem for template-based OCR software, for example, which may capture incorrect data if it appears in unexpected locations on the page. As a result, processing semi-structured forms requires more advanced OCR solutions capable of adapting to these inconsistencies.
Different types of forms impact OCR software accuracy differently. Structured forms with consistent layouts deliver high accuracy, while unstructured forms like emails pose challenges. Semi-structured forms, with some consistency but variable elements, require adaptable OCR solutions.
When choosing any OCR solution, consider form and image types, advanced features of software, AI and Machine Learning capabilities, and integration to ensure efficient document and image handling. Intelligent OCRs that are powered with AI can handle all kinds of structured and unstructured with a very high rate of accuracy.
Process of extracting data from forms
Let’s take a look at the steps involved in OCR form processing:
- Scanning or pre-processing: This step involves scanning physical documents or receiving digital documents. If the documents are already scanned, pre-processing may include tasks such as image enhancement to improve quality and clarity, noise reduction, and skew correction to ensure the document is properly aligned.
- Format and content detection: Once the document is prepared, the OCR software needs to identify the format and layout of the document. This involves detecting text blocks, fields, tables, and other structural components.
For structured forms, this step is relatively straightforward. However, for unstructured or semi-structured forms, this step can be more challenging due to the lack of a predefined layout. - Character recognition: In OCR form processing, detecting lines and visual features is crucial for accurate table extraction. Basic character recognition isn’t enough, making table extraction a challenge. Computer vision and machine learning algorithms add context to the extracted data.
- Post-processing: Once the characters are recognized, post-processing steps improve the accuracy and usability of the extracted data. Post-processing may also involve data formatting and integration into databases or other systems for further analysis or processing.
- Output: The extracted data is organized into structured formats such as tables, spreadsheets, or databases. The digital data is stored in a central repository or cloud storage of the organization. Authorized users can access the digitized and structured data for various purposes.
Role of OCR in automating data entry
OCR is necessary for automating data entry. It converts scanned documents, PDFs, and images into editable text, reducing the need for manual data entry. It saves time, minimizes errors, and improves efficiency. OCR also helps digitize records, easing recovery and management of data, leading to better decision-making and increased productivity.
Benefits of using OCR for forms
There are several benefits to employing OCR for forms. Some are evident, others—not so much.
Increases efficiency in data processing
OCR technology accelerates data processing by quickly converting physical documents from PDF forms into digital format. This rapid transformation enhances data validation and workflow efficiency, allowing organizations to handle large volumes of forms swiftly and accurately.
Reduction in manual errors
By automating data entry, OCR minimizes human errors occurring often during manual input and data validation. This ensures higher data accuracy, leading to higher precision and more reliable and consistent records.
Time and cost saving
Implementing OCR tools reduces the time spent on manual data entry and decreases labor costs for relevant data. It allows employees to focus on more critical tasks, optimizing resource allocation and operational costs.
Process automation
OCR facilitates the automation of various processes by integrating with other digital systems. This seamless integration enhances overall productivity and enables businesses to streamline their operations, resulting in a more efficient workflow.
Applications of OCR form processing
OCR software for automated form and document processing is used across various industries such as healthcare, finance, legal, education, healthcare, government agencies, human resources, retail, real estate, insurance, manufacturing, and more.
This versatility and value stems from the software’s use of deep learning for data extraction, which surpasses traditional rule-based template text extraction methods.
Here are some use cases and examples to help you understand its value and importance effectively:
- Loan application: OCR software streamlines the loan application process by automating data extraction from documents like ID proofs and income statements. This reduces manual data entry and minimizes errors, speeding up processing time.
Additionally, it converts paper documents into digital formats for easier storage and management. By verifying document authenticity and ensuring regulatory compliance, OCR enhances the security and reliability of loan approvals. - Bank account forms: OCR software streamlines the processing of bank account forms by automatically extracting information from documents such as ID proofs, address verifications, and income statements. It reduces the need for manual data entry, minimizing errors and speeding up the account opening process.
By digitizing paper forms, OCR makes it easier to store, retrieve, and manage customer records. Additionally, it helps verify document authenticity and ensures compliance with regulatory requirements, enhancing the security and reliability of the account opening process. - Insurance forms: OCR software eases the processing of insurance forms through automated data extraction from documents that include policy applications, claims, and ID proof. The software, therefore, necessitates less manual data entry in such documents, reducing mistakes and the processing period significantly.
OCR also facilitates easier storage, retrieval, and maintenance of insurance records by electronically converting paper documents into digital formats. The software is also critical in document verification to ascertain authenticity and maintain legal compliance, thus making the insurance process more accurate and reliable. - Employee forms: OCR software can streamline employee form processing by automatically extracting data from numerous documents, including employment applications, tax forms, and identification proofs. Additionally, OCR software can streamline the processing of other forms, such as job applications, resumes, and employee information forms.
This eliminates the need for manual data input, which reduces the need for data and speeds up the onboarding media Process. OCR makes it easier to store, retrieve, and manage paper forms by digitizing them.
Challenges and solutions
Here are the most common challenges in OCR form processing:
- Accuracy: Structured forms have a predefined format- for instance, tax forms or surveys. While OCR is effective with these forms, it’s never entirely accurate. In contrast, semi-structured forms, like invoices or contracts, have a more flexible layout. OCR struggles even more with these forms, further compromising accuracy during processing.
- Formats, fonts, and handwriting: These present significant challenges for OCR software. Complex layouts, such as those with multiple columns, tables, or graphs, interfere with text recognition and segmentation. OCR works best with standard fonts and Latin alphabets, struggling with unique fonts and non-Latin scripts.
Handwriting variability, including cursive writing and inconsistent clarity, further complicates accurate text recognition. These factors limit OCR’s effectiveness, often requiring specialized tools or manual intervention for precise results. - Watermarks and holograms: watermarks and holograms are troublesome for OCR systems. They can hide the text below or deform it, meaning that OCR systems will face problems accurately identifying and retrieving it.
Watermarks can create a background that will diminish text visibility, while holograms can reflect light and create different intensity levels that complicate text retrieval. That is why visual disturbances bring down OCR accuracy, which often results in extra processing time or the need for manual approval to guarantee accurate data retrieval. - Image quality: Image quality significantly impacts the performance of OCR software. Factors such as resolution, lighting, contrast, and noise play crucial roles in the accuracy of text recognition. Low-resolution images may result in blurred or pixelated text, making it difficult for OCR systems to accurately identify characters.
Poor lighting and contrast can obscure text details, while image noise can introduce random variations that interfere with text recognition. Consequently, poor image quality often leads to higher error rates and misrecognition in OCR processing. - Multilingual content: Multilingual content poses a substantial challenge for OCR software. While many OCR systems are optimized for the Latin alphabet, they often struggle with non-Latin scripts such as Cyrillic, Chinese, Arabic, or Hindi. Each language has unique characters, structures, and fonts that require specialized training and algorithms.
Additionally, documents containing multiple languages or mixed scripts can further complicate the recognition process, leading to increased errors and reduced accuracy. This limitation necessitates the use of advanced OCR systems or language-specific models to handle multilingual content effectively.
Strategies to overcome OCR implementation hurdles
HyperVerge’s AI-powered OCR solution offers a seamless, template-agnostic text extraction engine capable of extracting data from any document globally with 90%+ accuracy. It excels in handling structured and unstructured documents, achieving over 95% accuracy for global ID cards and official documents while effectively processing diverse templates like insurance forms, invoices, receipts, and bank statements.
The solution supports multilingual document processing in over 150 languages, leveraging a 13-year-trained AI model for exceptional accuracy from day one. Users can easily upload various document formats, capture and extract necessary information, analyze and extract it, and transform extracted data into ready-to-use structured fields.
HyperVerge supports a wide range of documents, including government IDs, financial records, legal contracts, and commercial documents, ensuring high accuracy and efficiency across all types.
Future trends in OCR technology
- Advancements in OCR for Forms: The future of OCR technology is bright and will expand to manage both structured and unstructured forms. Algorithms will improve, increasing the precision and overall speed of data extraction, especially in complicated layouts and document types.
- Integration with AI and Machine Learning: OCR technology will be integrated with AI and machine learning, making them smarter and more flexible. This means that OCR solutions will be allowed to learn and code themselves as new document types and additional languages are presented to them. With AI, OCR will have pattern recognition and contextual meaning-making abilities, which will reduce errors and encourage end-to-end AI-driven data extraction.
- Predictions for the Future of OCR in Form Processing: In the future, OCR technology advances will become even more widespread and specialized, with use cases extending into other industries. OCR is expected to help automate workflows, minimize residual times, and improve data accuracy within finance, healthcare, logistics, and government sectors. In turn, the advancement of AI and machine learning to enhance the technology too quickly will make it a disruptive class in efficient and dependable form processing.
Conclusion
Here are some key points from our article:
- Businesses and financial institutions face challenges handling large volumes of documentation, including forms, invoices, and transactional details.
- Manual processing is time-consuming, prompting the adoption of Optical Character Recognition (OCR) technology for digitizing documents.
- Modern OCR software increases speed and accuracy, improving operational efficiency and productivity in managing information.
- Future trends in OCR technology include advancements in handling structured and unstructured forms, integration with AI and machine learning, and predictions for broader applications across various industries.
- These advancements in OCR technology will lead to automated workflows, reduced processing times, and improved data accuracy, making OCR an essential tool for efficient and accurate form processing.
Ready to streamline your workflow? Say goodbye to manual processes and hello to streamlined operations with HyperVerge’s OCR Software.



