








It’s Tuesday morning. Your team should be focused on high-value tasks—closing deals, approving loans, or onboarding new clients.
Instead, they’re buried under a pile of invoices, identity documents, and contracts, manually fixing errors flagged by the system—misread dates, missing fields, or formatting mismatches.
A waste of time, resources, and money, not to mention the risk of fraud or compliance failures due to unverified documents.
This isn’t how businesses should be operating in 2025. Especially when AI can streamline end-to-end document processing, making it faster, more accurate, and truly efficient.
Let’s understand how AI-powered document processing can transform your onboarding processes.
Understanding Document Processing
Document processing is the process of analyzing physical and digital documents, extracting information, and converting it into structured data for businesses to use effortlessly.
Traditionally, businesses relied on manual data entry to build structured databases. Data operators read through pages, searching for relevant details and key fields, and even then the errors were prominent.
Manual document processing was slow, often taking hours or even days to complete. And, as document volumes grew, errors became unavoidable. The resulting database neither improved decision-making nor streamlined operations.
To speed things up, businesses adopted Optical Character Recognition (OCR) technology. OCR could convert scanned documents and images of typed, handwritten, or printed text into machine-readable formats without requiring extensive manual inputs.
However, traditional OCR had limitations. Its rule-based approach worked well only with structured documents—those following a fixed format. But most business documents, around 80–90%, are unstructured or semi-structured. And, that’s where OCR struggles.
To truly automate document processing, businesses needed more—something faster, smarter, and adaptable. This is where AI changed the game.
Understanding AI-Powered OCR: A Simple Breakdown
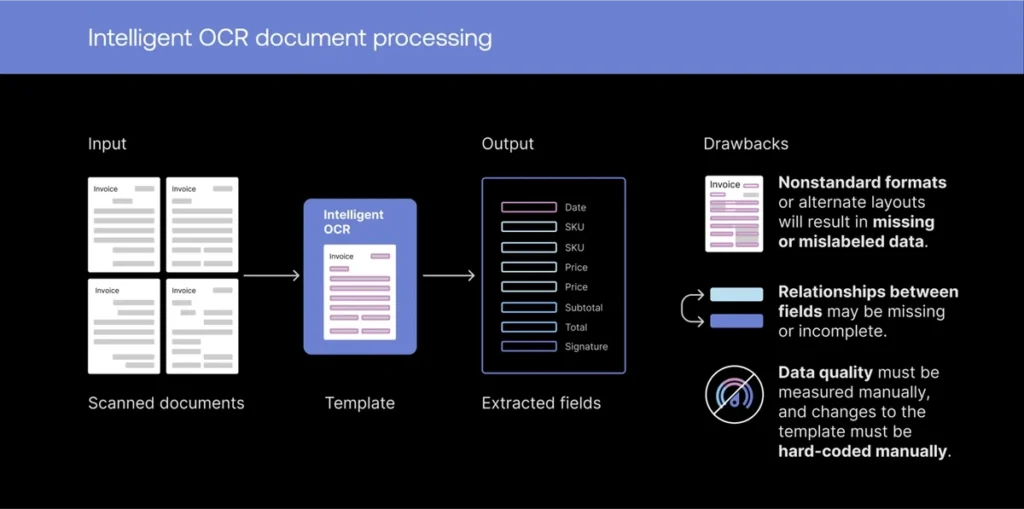
AI-powered OCR takes traditional document processing a step further by integrating machine learning (ML), deep learning, and natural language processing (NLP) into the OCR technology.
Here’s a quick rundown of differences to understand how AI-powered OCR differs from traditional OCR.
| Feature | Traditional optical character recognition (OCR) | AI-powered optical character recognition (OCR) |
| Technology | Rule based technology that follows the fixed template for data extraction | Template agnostic OCR engine for adaptive and context-aware recognition |
| Documents | Limited to structured documents with fixed layouts | Can process structured, unstructured, and semi-structured document formats |
| Text support | Can only extract printed or typewritten text in fixed fonts | Has an ICR (intelligent character recognition) that can also process handwritten characters |
| Document quality | Can only extract data from high-quality scans | Can reconstruct missing or distorted text from low-quality scans of paper documents |
| Data extraction | Extracts raw text but cannot assign meaning | Understands context and can establish relationships between key details |
| Data accuracy | Even the smallest layout variation can reduce accuracy | Up to 99% accuracy even in dynamically changing documents |
| Data validation and fraud detection | Cannot validate the document or detect fraud | Can identify altered, tampered, or fake documents by running documents against databases |
| Languages | Limited predefined languages and struggles with multiple scripts in same document | Supports multiple languages, dialects, and mixed-script documents, |
| Scalability | Limited scalability—accuracy drops with high document volume and format variety. | Highly scalable, handling millions of documents without loss in accuracy. |
| Processing speed | Fast but requires frequent manual verification | Processes documents in real-time, reducing manual intervention and improving turnaround time |
While AI-powered OCR significantly improves text extraction, businesses often need more than just recognition—they need an end-to-end system that automates document workflows. This is where Intelligent Document Processing (IDP) comes in.
IDP goes beyond text extraction. It understands context, validates data, and automates end-to-end processes. This makes document processing more accurate, efficient, and fraud-resistant.
The role of AI in modern document processing
Any document processing software is AI-powered these days. But what exactly is the role of AI in this space?
Let’s understand that:
Automating data extraction
AI automates the entire process of data extraction by seamlessly pulling the information you need from any document. It adapts to different formats and recognizes key fields even in complex documents such as invoices, ID proofs, financial documents, contracts, and handwritten forms—all without requiring extensive manual intervention.
Machine learning algorithms further refine the process by learning from previous outputs, feedback, and training datasets. This ensures that AI does not repeat past errors, enhancing accuracy and efficiency in future document classification and processing.
Here are a few ways AI automates data extraction:
- Detects and extracts relevant data such as names, addresses, dates, invoice numbers, and account details from documents
- Accurately map data by recognizing tabular data in bank statements, insurance forms, and reports
- Uses Intelligent Character Recognition (ICR) to extract handwritten information from applications, signatures, and medical records
- Recaptures missing and distorted information putting NLP and ML algorithms to use
Example: A retail chain receives thousands of invoices from suppliers in varied formats every month. An AI document processing tool automatically extracts key details like vendor name, invoice number, and payment amount, validates them against purchase orders, and flags discrepancies.
Also read: ID OCR: How To Extract Information From Identity Documents
Streamlining onboarding process
The entire onboarding process from document submission to verification, approval, and compliance becomes faster and more efficient with AI. With AI-powered OCR, businesses don’t need to manually enter details. The system auto-fills forms, runs background checks, validates extracted data against regulatory databases, and detects discrepancies—all while significantly reducing turnaround time.
Here’s how document processing platforms streamline onboarding with AI:
- Minimizes onboarding risks by instantly flagging missing, mismatched, or fraudulent details in documents
- Automates compliance by cross-referencing extracted data with government and financial databases
- Reduces manual errors by validating document details against pre-set rules
- Intelligent decision engines approve, reject, or flag applications based on risk scores and policy compliance
- Enhances decision-making by structuring and analyzing onboarding data for risk assessment and approvals
Example: A fintech company receives thousands of new customer applications daily. AI-powered OCR extracts identity details, verifies them against official databases, and flags fraudulent attempts, allowing for instant approvals and compliance checks.
Real-time document verification
Intelligent document processing work in real-time to validate customer documents without long processing times. It operates seamlessly, detecting even the slightest inconsistencies in documents to prevent fraud and ensure accuracy.
Here’s how AI helps in detecting inconsistencies:
- Detects tampered or manipulated documents by analyzing security features, metadata, and inconsistencies
- Identifies duplicate submissions by recognizing patterns and anomalies in document entries
- Flags mismatched details such as name, date of birth, or address discrepancies in submitted documents
Example: A digital lending platform receives loan applications with uploaded ID proofs and income documents. AI-powered document verification analyzes document authenticity and flags mismatched details. This allows lenders to instantly approve genuine applications while preventing fraud.
That said, AI can help automate document-heavy processes from invoice processing and identity verification to contract management and compliance documentation. It helps reduce human error and improves accuracy across industries.
Also read: OCR Automation: How to Leverage Automated OCR Workflow
Combating ID Forgery with AI-Powered Document Processing

According to Entrust’s 2025 Identity Fraud report, digital document forgeries have increased 244% year-over-year. This was also the first year, where digital forgeries surpassed the forgery of paper-based documents, accounting for nearly 57% of all document fraud.
As fraud and the forms of fraud continue to evolve, businesses need advanced verification methods that can detect inconsistencies, alterations, and digital manipulations promptly. Of course, AI factors in, and here’s how:
- Detecting fake documents: AI can instantly capture fake security features such as holograms, watermarks, and microprints by comparing these elements with authentic government-issued templates
- Spotting digital manipulations: AI-powered OCR, combined with computer vision and deep learning, detects Photoshop alterations, pixel inconsistencies, and layer modifications by analyzing text spacing, font anomalies, and metadata discrepancies
- Cross-checking databases: AI compares ID details such as name, date of birth, and document number with official government, financial, and regulatory databases
- Preventing identity theft: AI detects suspicious patterns, duplicate identities, and forged documents by analyzing biometric data, behavioral inconsistencies, and historical records. If anomalies are found, it instantly flags the application for further review or rejection, preventing identity fraud in real time
The AI-powered document processing solution detects forged IDs, spots digital manipulations, and prevents identity theft, ensuring you only onboard genuine users with verified documents.
Benefits of AI-Powered Document Processing in Onboarding
Let’s have a quick rundown of the benefits your business gains by automating onboarding document processing with AI:
- Speedy onboarding: Reduces processing time by extracting and validating KYC documents, passports, and financial records in real time for instant approvals
- Enhanced fraud detection: Detects even the most sophisticated forgeries in bank statements, ID proofs, and income documents by analyzing complex patterns, linguistic features, and contextual data
- Ensures security compliance: Cross-references identity documents against government and financial databases to prevent fraud in regulated industries like banking and insurance
- Slashes operational costs: Eliminates the need for manual data entry and validation in high-volume onboarding processes, such as loan applications and employee background checks
- Enhanced customer experience: Eliminates paperwork delays and streamlines digital onboarding for fintech apps, digital banking, and online marketplaces, reducing drop-offs
Also read: HyperVerge OCR Solution: Benefits & Features
Overcoming challenges: implementing AI in your business
Adopting AI-powered OCR for document processing can transform business operations. However, there are certain challenges with AI adoption and implementation which may slow down integration, affect data accuracy, or create compliance risks.
Here’s how to address these challenges effectively.
1. High implementation costs & unclear ROI
Challenge: Businesses hesitate to invest in AI due to uncertain ROI and high initial deployment costs
Solution: Start with high-impact use cases like KYC verification or invoice automation to demonstrate immediate cost savings and efficiency gains
2. Employee resistance & skill gaps
Challenge: Employees may resist AI-powered OCR due to lack of familiarity, fear of job displacement, or concerns about workflow changes
Solution: Implement hands-on training and phased AI adoption, ensuring AI works alongside employees rather than replacing them
3. Integration with existing workflows
Challenge: Certain document processing software struggle to integrate with legacy systems, CRMs, and ERPs, causing workflow disruptions and IT complexities
Solution: Opt for API-driven OCR solutions that enable seamless plug-and-play integration, reducing downtime and manual intervention
4. Compliance & data privacy risks
Challenge: Handling sensitive data raises concerns about regulatory compliance with KYC, AML, and data protection guidelines
Solution: Use AI-powered OCR with secure data storage, end-to-end encryption, role-based access, and built-in compliance checks to prevent unauthorized data exposure
5. Poor quality data
Challenge: Most businesses struggle with unstructured data, low-quality scans, and incomplete documents
Solution: Implement real-time quality checks to flag low-quality uploads and prompt users for better versions.
6. Limited support
Challenge: Some AI-powered OCR providers lack dedicated support for integration, troubleshooting, or implementation, making adoption difficult for businesses
Solution: Choose the right document processing tool that offers comprehensive onboarding, API documentation, and ongoing technical support to ensure a smooth transition and minimal disruptions
Also Read: A Buyer’s Guide To Choosing The Best OCR Software
Future Trends: What’s Next in AI-Powered Document Processing?
As AI continues to evolve, document processing is becoming smarter, faster, and more secure. Emerging technologies within the AI landscape are further enhancing accuracy, helping businesses not only automate data extraction but also strengthen compliance and improve decision-making.
As we move through 2025, here are a few trends that are shaping the future of document processing:
- Machine Learning algorithms will enhance the accuracy of processed documents and reduce false positives by learning from the previous outputs, feedback, and training datasets
- Blockchain will add a layer of security, making your documents tamper-proof and offering verifiable audit trails for enhanced trust and compliance.
- Combining facial recognition, fingerprint scans, and liveness detection ensures that documents are not just valid but also linked to the rightful user, reducing identity fraud risks.
AI-driven document processing is the need of the hour, not just a nice-to-have. Businesses must protect genuine customers while keeping fraudsters out, and AI is making that possible with faster, smarter, and more secure verification.
With Hyperverge’s AI-powered OCR, you can extract data from any document globally with up to 95% accuracy. We offer seamless multilingual document processing with our seamless plug-and-play API.



