






Extract data from any document globally.
AI-powered, template-agnostic OCR engine with
90%+ accuracy across the globe.
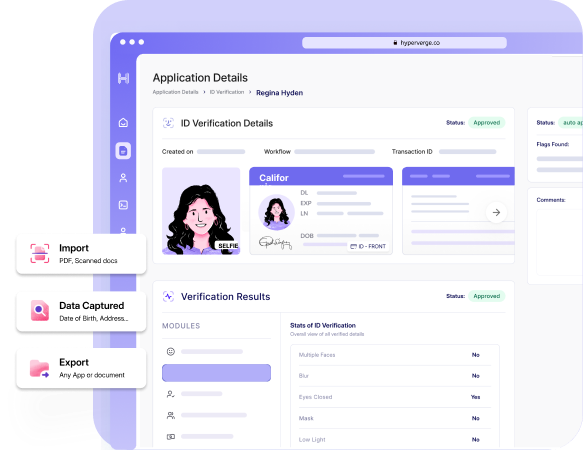
Seamless OCR solution
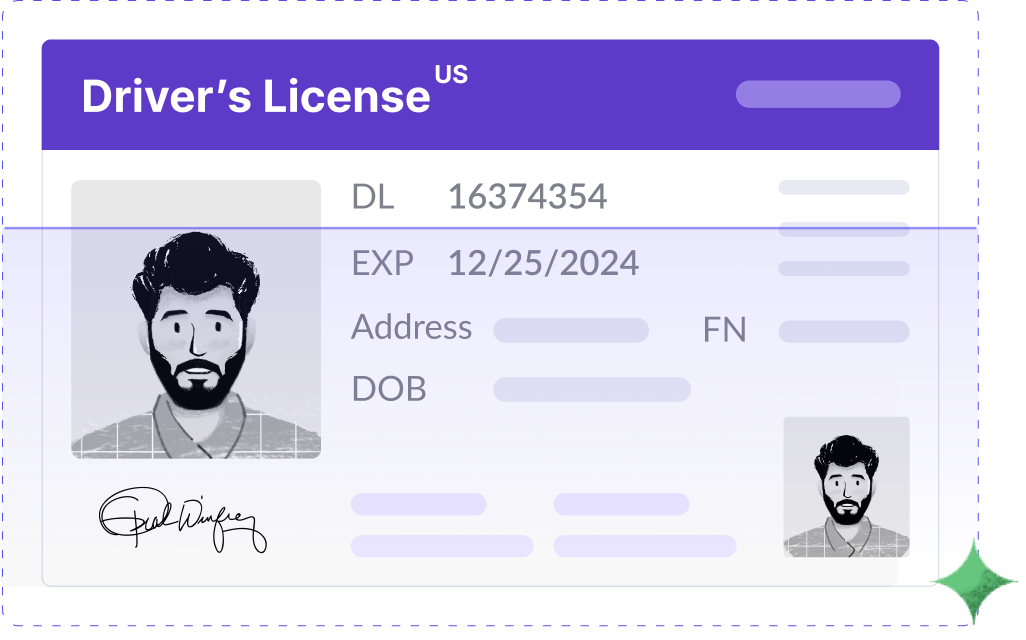



OCR for Structured Documents
Extract text with 95%+ accuracy from global ID cards and official documents, capturing key fields automatically.

OCR for Unstructured Documents
Extract data from unstructured documents and diverse templates like insurance forms, invoices, and bank statements.
Seamless Multilingual Document Processing
Break language barriers and process hundreds of global documents in 150+ languages.
AI-powered Optical Character Recognition
Leverage a 13-year-trained AI model for OCR with exceptional accuracy and reliability from day 1.
How HyperVerge OCR Solution Works

Seamless Document Import
Easily upload various document formats such as PDFs or images.

Intelligent Document Processing
Capture the information you need from the scanned documents.

Structured Data Classification
Represent extracted data dump into ready-to-use structured and appropriate fields.
Documents Supported
Government ID cards
Driving license
Passports
Bank checks
Payroll slips
Entity registration
Proof of delivery
Bank statements
Purchase order
Tax documents
Property documents
Utility bills
Legal contracts
Bill of lading
Insurance documents

OCR Maturity Model: Moving Beyond Templates
to Artificial Intelligence
We are compliant and secure at our core

Encrypt user details to prevent data breach

Stay compliant with global regulations

Maintain audit trail of every application

#1 in Global Face
Recognition in US & APAC

AICPA | SOC2

General Data
Protection Regulation

ISO 27018

Financial Action
Task Force

Best-in-class
Regtech solution 2022

Best in Liveness
G2 Rating for HyperVerge
4.7





Why HyperVerge OCR

Turbocharge Your
Process Efficiency
Unleash enhanced efficiency and slash turnaround times. Automate manual processes and accelerate your journey to go-live sooner than ever.

Rapid Adaptability, Unmatched Precision
Want to extract data from a new document format? HyperVerge OCR can adapt a new document type within a week with a very small sample size — all while maintaining high accuracy.
Globalize with
Confidence
Go global swiftly with a template-agnostic OCR and ID verification engine. Navigate diverse markets and make your expansion efficient.
Trusted by startups and the world’s largest companies

Jio selects HyperVerge for lightning fast customer activations.
4 Days to 5 Mins
Activation Time reduced drastically
5X Speed
Revenue generated with fast activations
HyperVerge delivered way more than what was expected. Couldn’t have asked for more.

Kiran Thomas
President, Jio Telecom
Using HyperVerge’s OCR, Home Credit reduced error rates drastically
50%
Error Reduced
33%
Reduction in TAT
Two things – uptime and reduction error rates were the game-changers for us.

Vishal Sharma
Senior Vice President of Operations, Home CreditHyperVerge Tech helped WazirX in scaling up to millions of users
First 10 million+
Users onboarded seamlessly
30,000 KYCs/day
Handled hassle-free
It’s not only just about tech but also the user experience. HyperVerge does that really well & that’s their strength as well.

Siddharth Menon
C0-Founder, COO, WazirXMobile Premier League (MPL) used HyperVerge KYC to stop millions of bad actors
30%
Jump in accuracy
700+
KYCs processed a minute
We were able to reduce the number of cases of cyber crime complaints or chargebacks after we went live with HyperVerge.

Krishna Mohan Vedula
VP Payments, MPL


End-to-End Security and Compliance Assurance
#1 in Global Face
Recognition in US & APAC

AICPA | SOC2

iBeta
Quality Assurance

General Data
Protection Regulation

Best-in-class
Regtech solution 2022

What is an OCR software?
Optical Character Recognition (OCR), software is a technology that converts different types of documents, such as scanned paper documents, PDFs, or images, into editable and searchable data. It extracts text from these files, making it accessible and useful in various applications.
What is the difference between OCR and ICR?
OCR focuses on converting printed or typewritten text from documents in multiple languages into machine-readable text, while ICR, or Intelligent Character Recognition, goes a step further by recognizing and processing handwritten characters. Both technologies play vital roles in digitizing and extracting information from diverse sources.
What is the data extraction process from scanned documents and images?
Optical Character Recognition software scans content from multiple file formats, recognizes characters, and converts them into editable formats. This process facilitates efficient handling of information from paper documents, aiding tasks such as data entry, content digitization, and document organization.
How does OCR help identity verification?
OCR solutions capture data and text from identity documents, enabling automated identity proofing and KYC (Know Your Customer) compliance. Through identity verification checks, OCR helps verify customer identities, ensuring real identity validation. This is crucial in anti-money laundering and fraud prevention efforts, as it enhances the accuracy and efficiency of the verification process for both digital and paper documents.