Employing facial recognition algorithms in banking and financial services comes with concerns. In this blog, we discuss some of the AI-powered approaches that can be taken to avoid biasing facial recognition.
(This article is Part II of a three-part article on the evolution of facial recognition algorithms, the prevalence of biases in the algorithm, and how facial recognition bias can be reduced. In Part I, we looked at the advent of facial recognition technology and its evolution. Part III looks at how HyperVerge is working towards reducing bias.)
Measuring Accuracy
NIST regularly benchmarks systems, and in a 2018 test found that error rates have gone down to 0.2% from 4% in 2014.
For context, this is how HyperVerge FaceMatch fares on both overall accuracy and accuracy for different ethnicities –
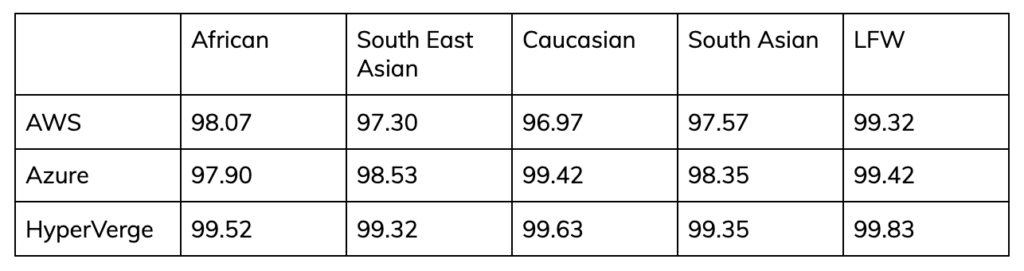
*Please note: for more details about the results displayed here, please contact us to see the algorithm in action.
Increasing Accuracy
Challenges with accuracy could fall under two categories:
- Quality of Images
- Quality of the Algorithms
Image Quality
Given that most commercial applications of facial recognition technology use still images, accuracy is challenged.
2D camera technology creates a flat map of the face shape. Algorithms calculate the relative position of ‘markers’ (like eyes, nose, lips) to turn them into an abstract feature representation. For use cases where one image is checked against many, recognition algorithms try to establish a match within the database. For one to one checks, the algorithm compares two extracted features (of the faces) with one another to establish a match.
In well-lit and stable environments, 2D technology works well but change of lighting, camera quality, or pose can introduce fraud into the process. Fraudsters commonly use photographs or pre-recorded videos to spoof. The algorithm is more likely to report false negatives in such cases.
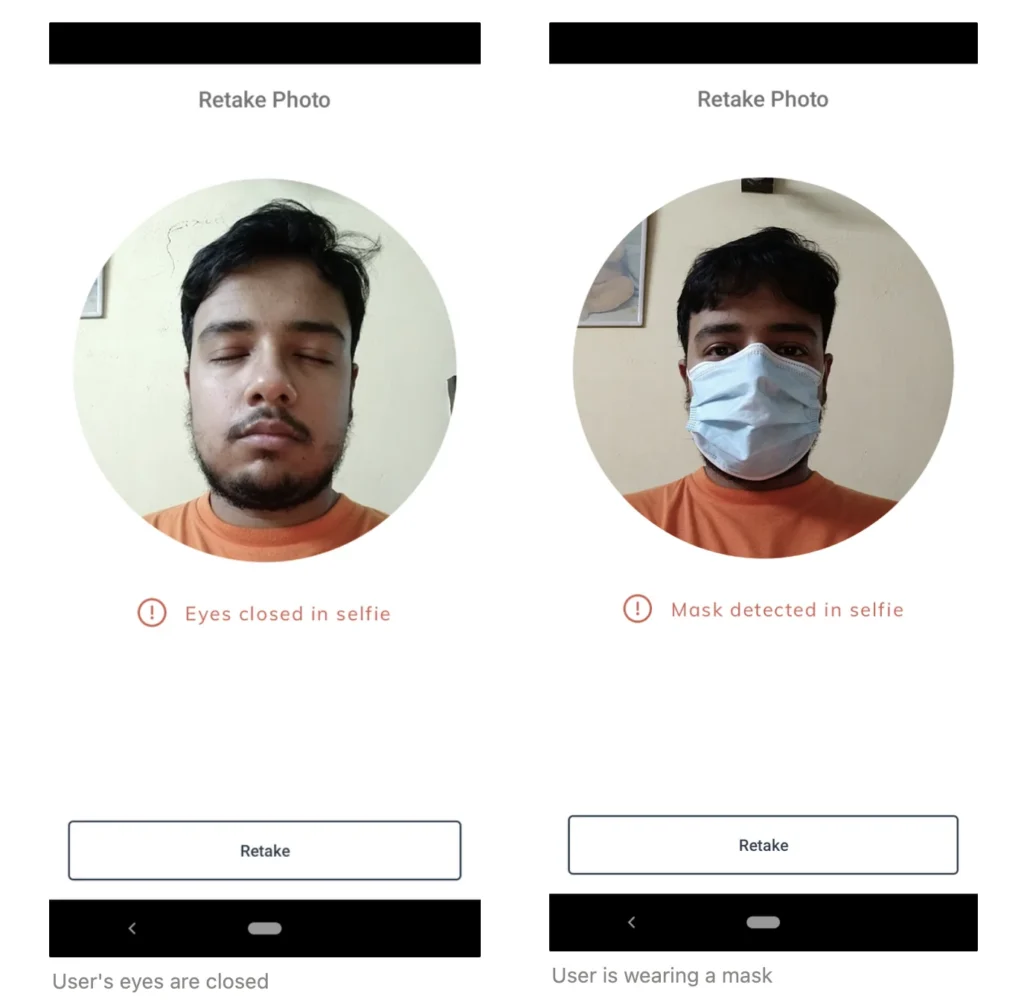
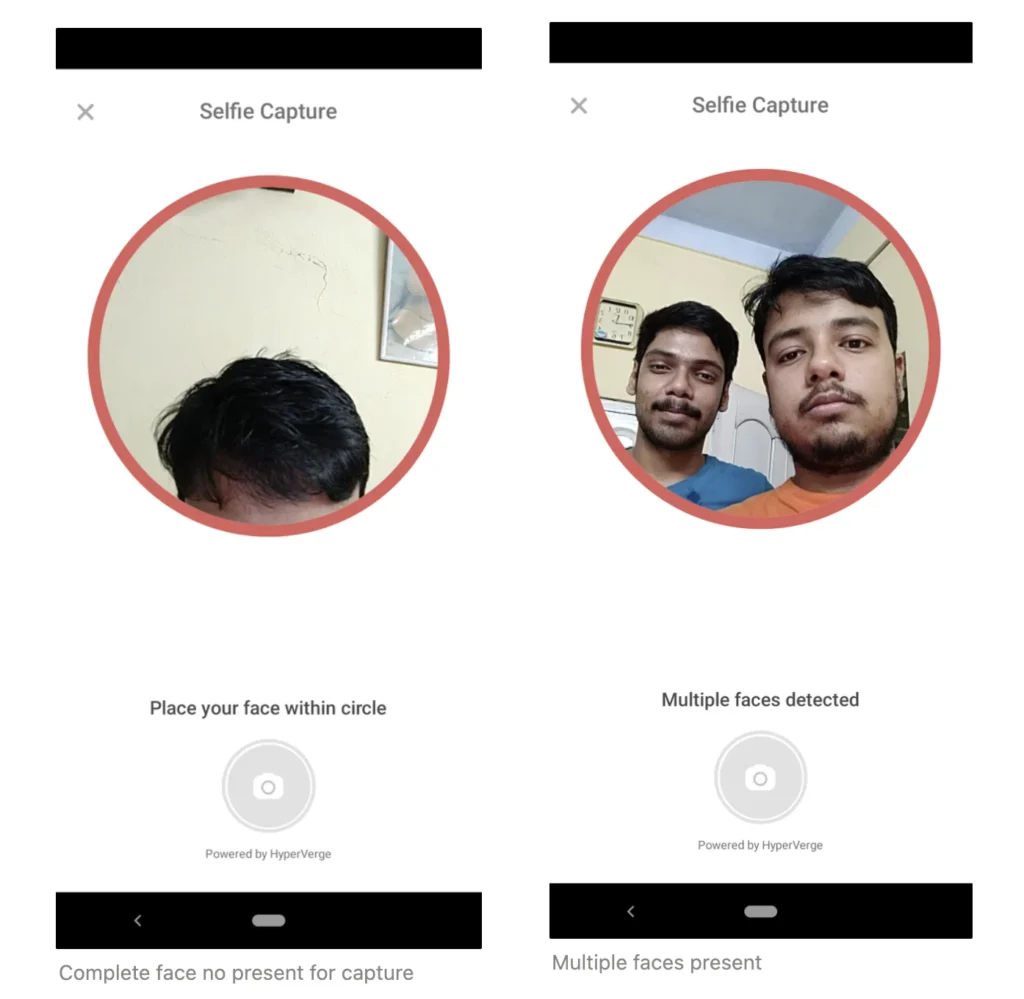
False negative error rates can be reduced by the introduction of:
- Standard-compliant images – a workflow mechanism that ensures that captured images meet quality requirements
- Deep convolutional neural networks – algorithms that can capture information even from substandard photos deviating from normal requirements
- Liveness check – an advanced technique that detects whether a user is physically present without requiring any explicit action or gesture, by analyzing light, skin texture, micro-motions, and other facial characteristics
Quality of Algorithms
There is currently — and rightfully — a sharp, global focus on making sure that algorithms don’t perpetuate or, worse, exacerbate the unfairness of existing social systems. In particular, algorithm-influenced decision-making poses dangers when data is imperfect, messy, or biased.
Specifically, algorithmic bias describes systematic and repeatable errors in a computer system that creates unfair outcomes, such as privileging one arbitrary group of users over others.
But it’s important to set context. While many studies have widely cited that face recognition is biased, the reporting stems from a confusion in terminology.
Differentiating between Recognition and Classification Bias
Face classification algorithms accept one face image sample and estimate factors such as age, or sex, or some other property of the subject.
Face recognition algorithms, on the other hand, operate as differential operators. They compare identity information in features vectors extracted from two face image samples and produce a measure of similarity between the two. Both one-to-one identity verification and one-to-many search algorithms, are built on this differential comparison.
The salient point, in the demographic context, is that one or two people are involved in a comparison and, the age, sex, race and other demographic properties of both will be material to the recognition outcome. However, the challenges are multifold.
Unconscious Bias
An algorithm might latch onto unimportant data and reinforce unintentional implicit biases. For instance, if the information fed into an algorithm shows that you live in an area where a lot of people have defaulted on their loans, the system may determine you are not reliable, It may also happen that the area may have a lot of people of certain minorities or other characteristics that could lead to a bias in the algorithm.
Lack of Data Governance
Given that algorithms are trained with data sets, if the data is biased, the algorithms will follow suit. Developers that train and test algorithms too often use data sets with poor representation of minorities. In fact, a commonly used dataset features 74% male faces and 83% white faces. Other commonly used datasets also show varying levels of bias towards Caucasian faces. If the source material is predominantly white, the results will be too.
This poses a significant problem for algorithms used in automatic demographic predictors and facial recognition software. Since facial recognition software is not trained on a wide range of minority faces, it misidentifies minorities based on a narrow range of features.
Ideal Solution
Wide-scale and standardized studies like the NIST’s help uncover common flaws in the algorithms. When the datasets and results are put to rigorous analysis, they provide an opportunity to improve the algorithm and thereby address the issue of bias in future iterations of the software.
Related read: Top 10 Face Recognition Software (Feature Checklist Included)
Solving the problem would require a multi-faceted solution that delivers across three critical areas.
Dataset Accuracy
Data can increase the potential biases of an algorithm. One way to avoid having different training models for different groups of people, especially if data is more limited for a minority group.
It isn’t possible to remove all biases from pre-existing data sets, especially since we can’t know what biases an algorithm developed on its own. Instead, we must continually re-train algorithms on data from real-world distributions.
Algorithm Regularization
For increasing accuracy, algorithm regularization techniques can be used. However, while the general learning capability is increased, it does not counteract prevalent bias in datasets.
Reducing bias would require regularizing an algorithm with an additional parameter that ensures equitable treatment of different classes. Regularizing not only aims to just fit historical data, but also to score well on some measure of fairness. This is usually done by including an extra parameter that penalizes the model if it treats certain classes differently.
Critical Design
Recent work has called attention to algorithmic discrimination and inequalities and identified the need for improved transparency and engagement. Notions of algorithmic fairness and accountability circulate in policy discussions and appear in regulatory standards and legislation such as the European GDPR and New York City’s algorithmic accountability bill.
As machine learning techniques become more prevalent, critical approaches need to be baked into designing for transparency and accountability of algorithms. One approach could be a human-centered algorithm design that focuses on a clearly participatory and politically aware participatory design approach to make algorithms better.
Curious about how HyperVerge addresses these challenges? Read Part III here.