Employing facial recognition algorithms in banking and financial services comes with concerns. In this blog, we discuss some of the AI-powered approaches that can be taken to avoid biasing facial recognition
(This article is Part I of a three-part article on the evolution of facial recognition algorithms, the prevalence of biases in the algorithm, and how its bias can be reduced. In Part II, we will look at how different algorithms compare, how facial recognition bias sneaks in, and how we can counter that. Part III looks at how HyperVerge is working towards reducing bias.)
In the pre-algorithmic world, humans and organizations made decisions in lending, hiring, and criminal sentencing based on manual evidence. These decisions were often governed by the federal, state, and local laws that regulated the decision-making processes in terms of fairness, transparency, and equity.
With the advent of facial recognition, algorithms are now trained to help make those decisions.
Facial Recognition: A Primer
Evolution of Algorithms
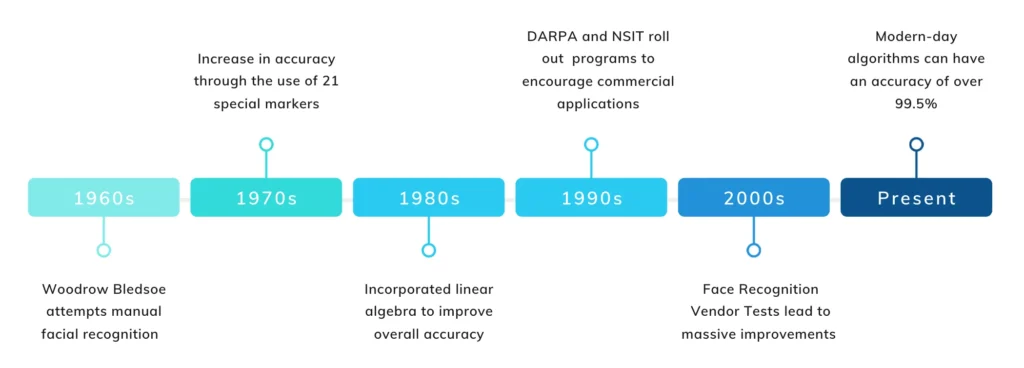
Pioneered by Bledsoe in the 1960s, the first facial recognition system allowed individuals to manually organize photos on a tablet by recording coordinates of various facial features into a database. Once the database received a new photograph, it retrieved the closest matches.
The technology improved in the ‘70s but calculations were still manually done and it was a labor intensive task. It was only in the ‘90s that commercial applications of facial recognition picked up.
The Defence Advanced Research Projects Agency (DARPA) and the National Institute of Standards and Technology (NIST) initiated a program to encourage the commercial sector to adopt the technology. The Face Recognition Technology (FERET) programme helped create a database of facial images starting with a small database of 2,413 images (compare that to databases in 2019 with up to 1 million images!).
Since then, the adoption of facial recognition technology has progressed monumentally.
Algorithms Today
Although the task of recognizing a face accurately is challenging, advancements in machine learning algorithms, processors and processing speeds, and cameras have made it less challenging in most aspects.
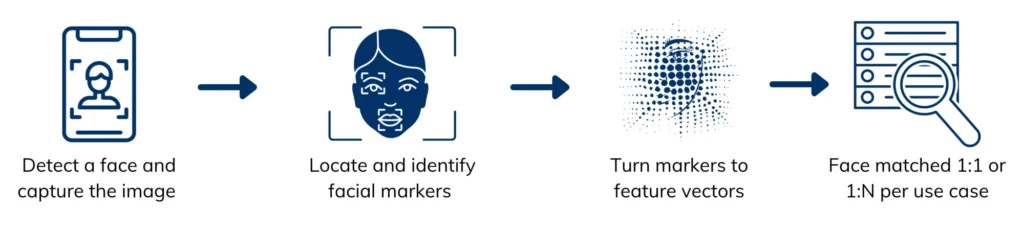
Modern algorithmic approaches involve detecting a face in an image and ‘learning’ it’s representation. This is usually done by two models – one which detects the face and another which converts the face to a feature vector. Both of them are trained on datasets for their respective purposes. These approaches have developed to an extent where algorithms can be used to identify a person amongst a million faces.
Now, you can pay for a burger in California with your face or worse, be denied entry at the Brit Awards since they use facial recognition to screen guests.
In banking and financial services, firms are adopting facial recognition to power applications across multiple points of contact. Major financial services firms offer customers the option to use facial recognition for logging into their mobile banking apps. Other apps provide users the ability to pay instantly using facial recognition.
However, in the case of a ride-sharing app, their facial recognition algorithm based on Microsoft’s Face Detection API has been in the eye of controversy due to reported inaccuracies and resultant repercussions. The app prompts drivers to share a selfie before going online, and matches that image to a picture the company has in its database. The algorithm, however, has a high error rate for recognition in case of dark-skinned individuals.
How does one benchmark existing solutions and work towards reducing bias? Read Part II here.