

Onboarding in BFSI is a balancing act: customers expect instant account openings, loan approvals, and policy issuances, while businesses need airtight compliance and fraud checks. In this journey, something as “simple” as a name match can become a silent deal-breaker.
Imagine this:
A customer applies for a ₹10 lakh personal loan. All documents are in order, but the application gets stuck because her PAN card says “Pooja Sharma” while her bank account reads “Puja Sharma.”
It’s a one-letter difference, yet enough for most systems to raise a red flag. The result? Delayed disbursal, a frustrated customer, and wasted operational effort.
This is the reality for banks, insurers, and NBFCs in India every single day. Why? Because in India, a customer’s name might appear slightly different across Aadhaar, PAN, and bank accounts. To a human reviewer, it’s obvious that Pooja Sharma and Puja Sharma are the same person. But for a rule-based system, this mismatch could trigger delays, manual reviews, or even rejections.
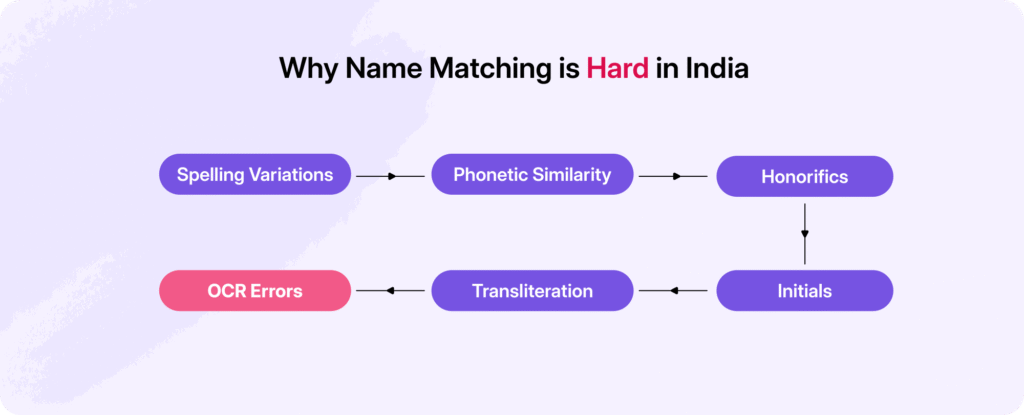
The Challenge: Why Indian Names Are Hard to Match
Matching names in India isn’t as easy as string comparison. The challenges are unique:
- Multiple formats across documents: A person may be “Ramesh Kumar” on Aadhaar, “Ramesh K.” on PAN, and “Kumar Ramesh” on their bank account.
- Cultural conventions: South Indian names often use initials instead of surnames. In parts of North India, honorifics like Shri or Smt. are used widely.
- Linguistic quirks: Transliteration from Hindi, Bengali, or Tamil scripts leads to variations (Shekhar vs Sekhar).
- Placeholder surnames: Many Indians use common placeholders like Kumar, Kumari, or Bhai.
- Phonetic spellings: “Pooja” vs “Puja” or “Raghavendra” vs “Raghavender.”
Business Impact
- False mismatches: Loan disbursals delayed.
- Manual reviews: Higher operational costs.
- Customer frustration: Drop-offs during onboarding.
Example: An NBFC processing a loan for Shiv K. Menon finds his PAN as Menon Shiv. The system flags a mismatch, prompting the case to be reviewed manually. Multiply this by thousands of applicants, and you have a massive operational drag.
Edge Cases That Break Normal Name Match APIs
In India, no two names are truly the same, thanks to cultural diversity, linguistic quirks, and data-entry errors. Traditional name-matching APIs, designed for Western naming conventions, often struggle to handle these complexities. HyperVerge, on the other hand, is designed ground up for India.
Here’s a closer look at the most common edge cases:
Spelling Variations
- Example: Sanchayan vs Sanchayn
- Problem: Small typos or alternative spellings (like “Anand” vs “Annand”) are common during manual form fills or data entry. Generic string-matching APIs flag these as mismatches, leading to false negatives.
- HyperVerge Fix: HV applies edit-distance tolerance combined with AI-driven similarity scoring. This allows for small character-level differences to be still treated as the same name without opening the door to fraud.
Phonetic Similarity
- Example: Pooja Sharma vs Puja Sharma
- Problem: In India, names are often spelled phonetically based on how they sound. “Shekhar” vs “Sekhar,” “Pooja” vs “Puja” are all valid but easily mismatched.
- HyperVerge Fix: HV uses phonetic algorithms enhanced with ML that group sound-alike names together. This ensures variations in spelling caused by phonetics don’t disrupt onboarding.
Honorifics & Titles
- Example: Mr. Ramesh Kumar vs Ramesh Kumar
- Problem: Indians frequently include honorifics (Mr., Mrs., Shri, Dr., Smt.) in their documents or forms. Traditional systems treat them as extra words and create mismatches.
- HyperVerge Fix: Prefixes and titles can be ignored based on client requirements, ensuring clean comparisons focused only on the actual name.
Placeholder Surnames
- Example: Amit Kumar vs Amit
- Problem: Words like Kumar, Kumari, or Bhai are widely used as fillers in surnames. They aren’t identity-defining but still appear in legal documents, confusing legacy systems.
- HyperVerge Fix: HV intelligently recognizes and ignores placeholder surnames in comparisons, ensuring smoother matches without raising unnecessary false negatives.
Initials vs Full Names
- Example: Shiv K. Menon vs Menon Shiv
- Problem: Initials are widely used in South India and in official documents. Traditional APIs struggle with abbreviation handling, expansions, and order swaps.
- HyperVerge Fix: HV performs initial expansion and order detection. “Shiv K. Menon” and “Menon Shiv” are matched correctly, with K understood as a possible middle/last name initial.
Order Variations
- Example: Rao Anil Kumar vs Anil Kumar Rao
- Problem: Different institutions store names in different orders, first-last vs last-first. This breaks rigid name-matching logic.
- HyperVerge Fix: HV uses flexible order recognition, understanding that word rearrangements in Indian names don’t necessarily imply a mismatch.
Transliteration from Regional Languages
- Example: Raghavender vs Raghavendra
- Problem: Transliteration of Indian names from scripts like Devanagari, Tamil, or Bengali introduces spelling inconsistencies.
- HyperVerge Fix: HV’s script-aware phonetic models account for transliteration quirks, ensuring Raghavender and Raghavendra are matched correctly.
Space Discrepancies
- Example: Varun MS vs Varun M S
- Problem: Extra or missing spaces in names are a common cause of false mismatches in rigid APIs.
- HyperVerge Fix: HV has smart spacing anomaly handling, which treats these as equivalent, without letting intentional manipulations slip through.
Abbreviations & Relationship Markers
- Example: Usha Gulwadi vs Usha w/o Ram Gulwadi
- Problem: Many official documents in India add relationship markers like w/o (wife of), s/o (son of), or d/o(daughter of). Conventional systems struggle to reconcile these.
HyperVerge Fix: HV employs relationship-aware parsing, intelligently ignoring or adjusting for these suffixes so that Usha Gulwadi still matches with Usha w/o Ram Gulwadi.
How HyperVerge’s Name Match Works Under the Hood
Traditional name-match solutions stop at fuzzy logic or simple phonetic checks. HyperVerge goes several layers deeper by blending rule-based intelligence with AI trained specifically for Indian BFSI contexts.
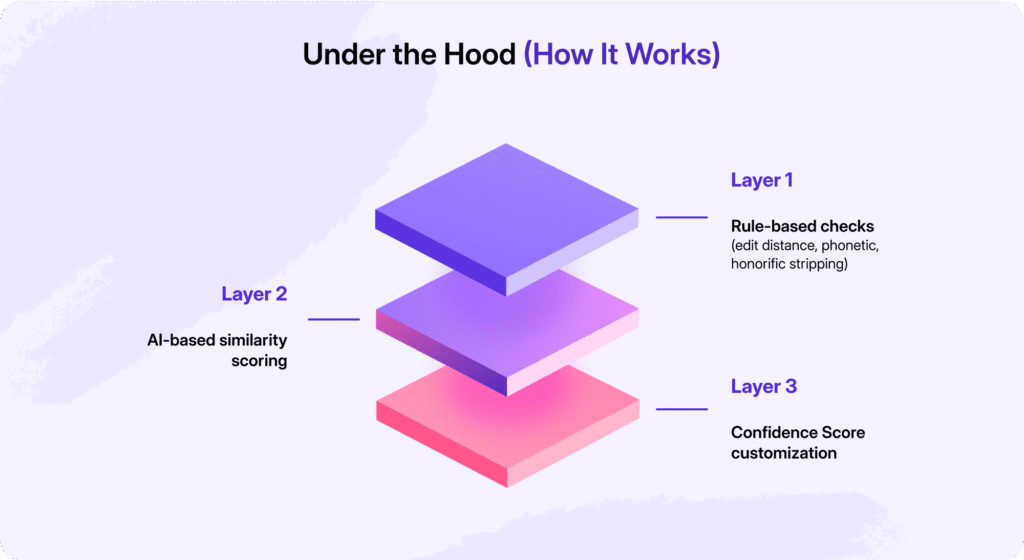
Here’s how it works:
- Rule-Based Matching:
At the foundation, HyperVerge uses tried-and-tested techniques such as edit distance (to catch typos), phonetic recognition (to match sound-alike names), and honorific stripping (to remove “Mr.”/“Shri”/“Dr.” that don’t add to identity). These rules act as the first filter. - AI-Based Matching:
Beyond rules, HyperVerge’s machine learning models are trained on millions of Indian KYC records across banking, insurance, and NBFC use cases. That means the system “understands” Indian naming quirks: from initials in the South to placeholder surnames in the North and adapts dynamically to them. - Confidence Score:
One-size-fits-all doesn’t work in compliance-heavy industries. That’s why HyperVerge provides customizable confidence thresholds. A bank processing high-value loans may want only near-perfect matches flagged as valid, while an insurance provider handling mass retail policies may prefer slightly looser matches for speed. HyperVerge’s scoring system allows this flexibility. - Global Strength, Local Precision: Unlike generic global solutions that struggle with regional complexities, HyperVerge brings a globally trained AI engine that is customizable for local contexts.
Where Name Match Matters Most in BFSI
The true value of name match comes alive when seen in real-world BFSI workflows. Here are some practical examples:
- Lending – Loan Disbursal:
A customer’s PAN card says Suresh Kumar while his bank account only has Suresh K. A normal API might block this, causing delays in loan disbursal. HyperVerge reconciles the initial vs full name instantly, so funds are released without bottlenecks. - Insurance – Policy Issuance:
OCR software reads Ramesh Kr. from a scanned application form, while the typed application says Ramesh Kumar. Generic systems reject this as a mismatch, delaying policy issuance. HyperVerge’s error-tolerant recognition smooths the discrepancy so the policy can be issued seamlessly. - NBFCs – Joint Accounts:
A husband and wife apply jointly for a loan. One document lists Arun & Priya Kumar in a single field, while another has Arun Kumar and Priya Kumar separately. HyperVerge intelligently parses and validates both entries without forcing manual intervention. - Fraud Prevention – Suspicious Identities:
A fraudster attempts to open multiple accounts by altering just one part of his name: Rohan Gupta in one, Rohit Gupta in another, both tied to the same PAN. Legacy APIs fail here because they see different names. HyperVerge flags this as a suspicious variation for manual review, preventing fraud.
Why Other APIs Fail Here
It’s tempting to think “name match is simple.” But when tested against India’s naming landscape, generic APIs consistently underperform. Here’s why:
- Generic fuzzy matching: They rely only on edit distance, which throws up too many false positives (e.g., matching completely different names that are just a few characters apart).
- No India-specific intelligence: They can’t handle initials, placeholder surnames, or honorifics, which are deeply embedded in Indian identity documents.
- Rigid rules: Global APIs usually assume Western-style first-last order. They fail when faced with rearrangements, middle initials, or joint entries.
Business impact: The result is a flood of manual reviews, longer onboarding times, frustrated customers, and even compliance risks when true mismatches slip through.
The HyperVerge Advantage
HyperVerge isn’t just another API; it’s a BFSI-grade solution built for India’s realities:
- India-first AI logic: Purpose-built to handle cultural, linguistic, and regulatory nuances in Indian KYC workflows.
- Scalable: Capable of processing millions of name checks per day, ensuring BFSI enterprises can grow without bottlenecks.
- Reduced manual reviews: Cuts operational costs drastically reduced resulting in faster TAT.
- Seamless integration: Works in real-time, embedding easily into onboarding journeys without adding friction.
- Customisable: Flexible confidence score tuning and edge-case handling based on each client’s risk appetite and workflows.
Best Practices for BFSI Teams
If you’re leading onboarding or compliance in BFSI, here are ways to maximize the value of name match:
- Use AI-based matching with customised confidence scores for customer-entered fields, where flexibility improves speed.
- Apply stricter, rule-based checks for compliance-critical flows like high-value lending or life insurance issuance.
- Combine name match with address match and ID number match for a holistic onboarding accuracy, reducing both fraud and false negatives.
Conclusion
In India’s BFSI landscape, a single mismatch can stall disbursals, frustrate customers, or let fraud slip through. Generic APIs break under India’s naming complexities. HyperVerge’s AI-first, India-specific solution ensures onboarding is fast, compliant, and customer-friendly.
See how your onboarding workflows handle edge cases in under 30 seconds with HyperVerge. Book a demo now!



