
Employing facial recognition algorithms in banking and financial services comes with concerns. In this blog, we discuss some of the AI-powered approaches that can be taken to avoid biasing facial recognition.
(This article is Part III of a three-part article on the evolution of facial recognition algorithms, the prevalence of biases in the algorithm, and how its bias can be reduced. In Part I, we looked at the advent of facial recognition technology and its evolution. Part II looked at how how different algorithms compare, how facial recognition bias sneaks in, and how we can counter that.)
How HyperVerge is Solving It
Solving the facial recognition puzzle for 410+ Million people across India, Vietnam, Indonesia, Philippines, and Singapore has taught us a thing or two about reducing bias and improving accuracy.
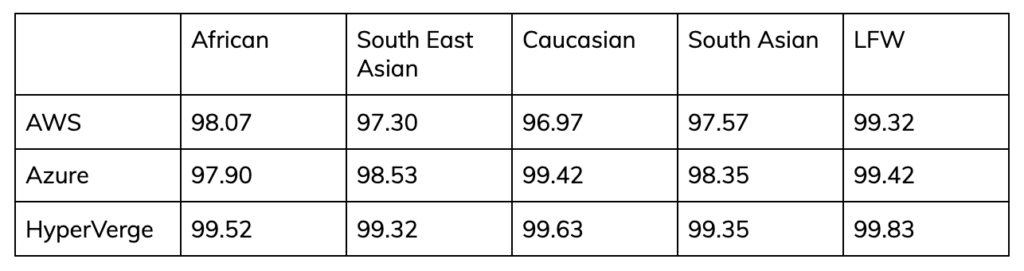
Improving Training Data
Algorithms are trained on datasets of millions of annotated images. If these datasets are poorly labelled, a self-training neural network will simply take that mislabeled data as fact. Thus, reproducing the error in the algorithm. That’s why it’s important to improve data quality. At HyperVerge, it’s done in two ways.
Balanced Dataset
HyperVerge ensures that the dataset used for training is class-balanced. A class-balanced dataset will have:
- Have a uniformly distributed sample size per class (each class represents a unique demographic)
- Ensure that the number of classes and the number of samples in one class are also balanced
Audited Datasets
Part of the process includes double-checking the dataset to ensure it meets internal standards. These standards account for client requirements and ensure that the demographic distribution in the dataset is representative of the distribution in the geography.
Addressing Algorithmic Bias
While acknowledging and mitigating hidden biases in the data is critical, algorithms also need to be designed to reduce such risks. HyperVerge’s Research team continuously develops and utilizes research that improves algorithmic accuracy and simultaneously reduces bias. Feature disentanglement is one of the critical methods we apply to improve the algorithm’s accuracy.
Feature Disentanglement in Facial Recognition
Let’s try to understand how the facial recognition algorithm attempts to learn the distinguishable features of facial regions for face identification in a bias-free manner.
We know that the color green is a mixture of blue and yellow, where blue is an individual’s real identity, and yellow represents the color of a person (or race or any other identity-irrelevant feature).
Using our facial recognition algorithm, we disentangle the blue and yellow components from green which allows us to compare two blue components (two unique identities) without any interference from the yellow filter. Similarly with actual faces, we disentangle a person’s identity from any racial markers and other identity-irrelevant features.
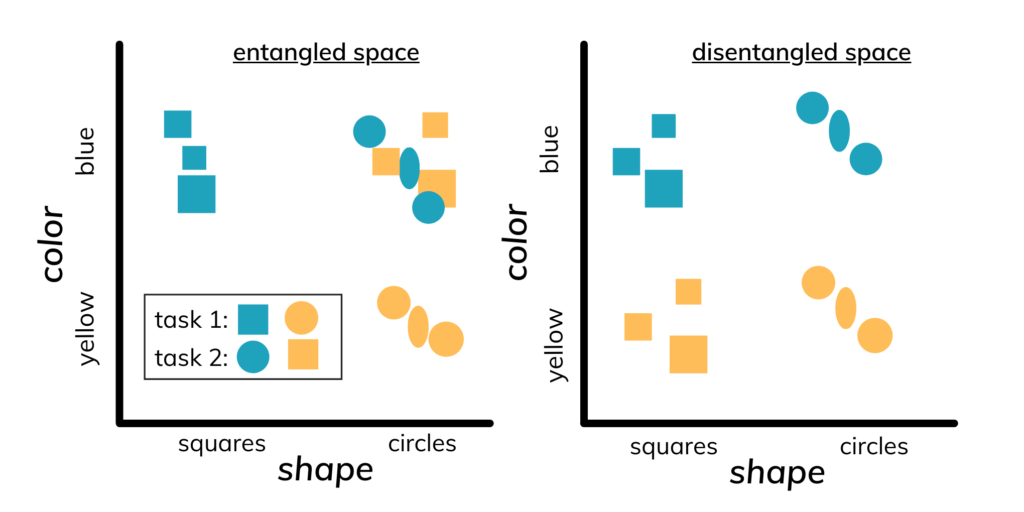
Disentangled features in faces are composed of identity-aware and identity-irrelevant features which are separated or disentangled from each other to assist with bias-free facial recognition.
The Way Forward for Equitable Algorithms
HyperVerge has verified 410 million identities with 99.5% accuracy in the last two years. Our experience with high-volume, large-scale implementation across geographies has ensured that our solution is robust and highly accurate. Additionally, our algorithms have also been at the forefront of the battle against newer and more imaginative forms of fraud within financial services, detecting fraud early on.
Apart from making the algorithms robust, we are invested in improving industry standards through rigorous research. HyperVerge’s specialized research team works on developing new machine learning models and refining existing models to turbocharge their accuracy.
Interested in seeing the algorithm in action? Our solution experts can help.
HyperVerge has enabled large organizations to safely authenticate and/or onboard millions of users over the past decade with minimal onboarding effort and turnaround time while ensuring protection against any fraudulent activity.
Large customers in telecom (Reliance Jio, Vodafone, etc), lending (Aditya Birla Capital, L&T Financial, EarlySalary, etc), securities (ICICI Securities, Angel Broking, Groww, etc), payments (Razorpay), e-commerce (Swiggy), and other industries trust HyperVerge’s onboarding solutions to safely onboard their users.
